In today’s data-driven world, research has evolved far beyond the traditional laboratory. Scientists now face a different kind of challenge — managing and making sense of massive, interconnected datasets. Whether it’s metabolomics, genomics, or artificial intelligence, researchers are surrounded by endless data but often lack the tools to interpret it efficiently.
That’s why, in 2025, the clustering search engine is emerging as one of the most transformative technologies for research. It’s not just a smarter search tool it’s a bridge between data chaos and scientific clarity.
The Data Discovery Dilemma in Modern Research
Every day, researchers produce terabytes of information — from mass spectrometry files and genetic sequences to clinical trial results and peer-reviewed publications. But accessing relevant information across such vast datasets remains one of the biggest bottlenecks in research productivity.
Traditional search engines rely on keyword matching. They list hundreds of results, many of which are repetitive or irrelevant. Researchers waste hours manually sorting, filtering, and cross-referencing to find meaningful connections.
A clustering search engine, however, changes this dynamic completely. It doesn’t just look for keywords — it understands context. It groups related search results into meaningful categories, allowing researchers to navigate complex datasets with speed and precision.
What Is a Clustering Search Engine?
A clustering search engine is a next-generation data discovery tool that organizes search results into thematic “clusters” instead of long, unstructured lists.
By analyzing patterns, semantics, and relationships between pieces of data, it helps researchers instantly identify groups of related findings — such as experiments, compounds, or publications — that share contextual meaning.
For example, if you search for “metabolic biomarkers,” a clustering search engine might generate clusters like:
-
Amino acid metabolism
-
Lipid oxidation pathways
-
Gut microbiome interactions
-
Mass spectrometry analysis methods
This structure allows users to dive into the most relevant topics instantly, eliminating the noise and redundancy typical of keyword searches.
How a Clustering Search Engine Works
Clustering search engines use machine learning and natural language processing (NLP) to recognize the meaning behind data. They employ unsupervised learning algorithms such as:
-
K-means clustering
-
Hierarchical clustering
-
DBSCAN or OPTICS
-
Word embeddings and vector similarity models
These algorithms detect semantic similarity between documents or data points. They don’t just see “words” — they understand that “lipid metabolism” and “fat oxidation” describe related biological processes.
By forming contextual clusters, these systems allow researchers to visualize how topics connect — something a conventional search engine simply can’t achieve.
Why Researchers in 2025 Can’t Ignore Clustering Search Engines
As research grows increasingly data-intensive, clustering search engines are becoming indispensable. Here’s why forward-thinking scientists are adopting them:
1. Faster Data Analysis
Clustering search engines reduce the time spent searching for information by grouping relevant results automatically. Instead of reading through hundreds of papers, researchers can focus on the clusters that matter most.
2. Contextual Understanding
Unlike keyword-based tools, clustering engines interpret meaning and relationships. This ensures more accurate and intuitive results — especially when working with scientific terminology that varies across disciplines.
3. Discovery of Hidden Patterns
Many groundbreaking discoveries come from unexpected connections. Clustering helps reveal hidden relationships between datasets — such as similar chemical properties, metabolic pathways, or experimental results.
4. Reduced Information Overload
With research data increasing exponentially, it’s easy to get lost. Clustering simplifies complexity, reducing mental fatigue and helping researchers stay focused on insights rather than sorting.
5. Seamless Integration with Analytical Tools
Modern clustering systems can integrate with laboratory information management systems (LIMS), data visualization platforms, and AI analytics tools, making them ideal companions for advanced scientific workflows.
How IROA Technologies Utilizes Clustering Search for Scientific Insight
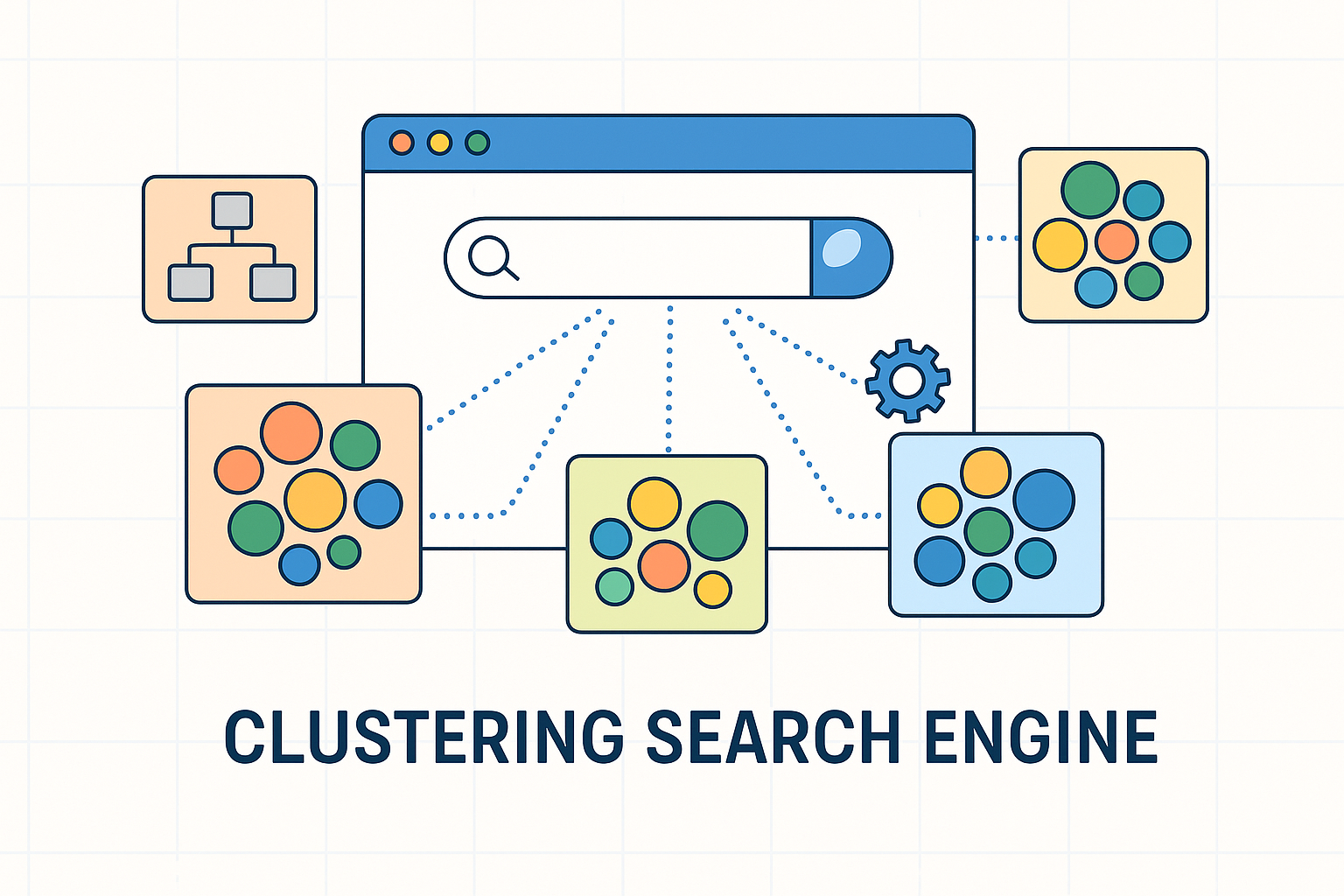 At IROA Technologies, we understand the importance of context and connectivity in data analysis. In metabolomics, where researchers often deal with thousands of peaks and compounds, traditional data handling isn’t enough.
At IROA Technologies, we understand the importance of context and connectivity in data analysis. In metabolomics, where researchers often deal with thousands of peaks and compounds, traditional data handling isn’t enough.
Our proprietary software, ClusterFinder™, applies clustering search engine principles to mass spectrometry data. It intelligently groups isotopic patterns, identifies biochemical relationships, and highlights co-eluting compounds — all in an intuitive interface.
This clustering approach empowers researchers to:
-
Visualize isotopolog patterns with greater clarity
-
Detect related metabolite groups automatically
-
Link biochemical data to metabolic pathways
-
Improve compound identification accuracy
By turning complex datasets into interpretable clusters, IROA Technologies enables scientists to make discoveries faster, with deeper confidence in their findings.
Real-World Applications of Clustering Search Engines
1. Metabolomics and Genomics
Researchers analyzing metabolic pathways or genetic variations use clustering to identify connections among thousands of compounds or gene expressions. This leads to faster biomarker identification and hypothesis generation.
2. Biomedical and Pharmaceutical Research
Drug developers use clustering search systems to analyze compounds, detect similar molecular structures, and discover potential therapeutic candidates more efficiently.
3. Environmental and Agricultural Science
From soil composition studies to climate data analysis, clustering helps researchers identify correlations between environmental variables and biological responses.
4. Artificial Intelligence and Knowledge Graphs
Clustering engines enhance AI applications by organizing unstructured data into interpretable knowledge graphs — a critical step in training intelligent models.
Advantages of Clustering Search Engines for Researchers
-
Improved accuracy: Clustering eliminates irrelevant results, presenting only contextually related information.
-
Enhanced visualization: Researchers can see how topics and datasets connect through clear graphical clusters.
-
Better collaboration: Different teams can find common ground even when using diverse terminologies.
-
Scalable performance: Whether it’s ten documents or ten million, clustering algorithms scale effortlessly.
-
Data-driven decisions: By identifying patterns early, researchers can steer projects more strategically.
The Future of Data Discovery
The future of research lies in intelligent data discovery — where AI not only organizes information but predicts what researchers might need next.
Soon, clustering search engines will:
-
Automatically recommend unexplored research areas
-
Generate visual maps linking concepts across disciplines
-
Learn from user behavior to refine search clusters dynamically
These advancements will turn the data deluge into an asset, not a burden, driving faster scientific breakthroughs.
Conclusion
In 2025, the clustering search engine has become an essential ally for modern researchers. It bridges the gap between overwhelming data and meaningful insight, enabling scientists to explore information more intuitively and productively.
At IROA Technologies, we are proud to integrate clustering intelligence into our tools like ClusterFinder™, empowering researchers to uncover patterns hidden in metabolomic and analytical datasets.
As the pace of discovery accelerates, adopting clustering-based systems isn’t just about efficiency — it’s about staying at the forefront of scientific innovation.
To explore how AI-powered research tools are transforming data discovery, visit Semantic Scholar.
FAQs About Clustering Search Engines
1. What’s the difference between a clustering search engine and a normal search engine?
A traditional search engine lists results by keyword relevance, while a clustering search engine groups them based on meaning and relationships, making research faster and more insightful.
2. Can clustering search engines handle scientific data like mass spectrometry or genomics?
Yes. Many advanced clustering systems, including those developed by IROA Technologies, are designed to interpret complex datasets in analytical chemistry and life sciences.
3. How does clustering improve research efficiency?
It reduces redundant searches, connects related information automatically, and helps visualize relationships — saving valuable research time.
4. Is clustering useful outside academia?
Absolutely. Industries such as pharmaceuticals, cybersecurity, and e-commerce use clustering to detect trends, anomalies, and customer behavior patterns.
5. What’s next for clustering search engines?
Future systems will combine predictive AI, natural language understanding, and visualization tools to deliver proactive insights instead of reactive results.